One major piece of functionality that is missing from the core Text Layout Framework libraries is a means of converting the many forms of XHTML-based content into usable TLF formats. There are significant "interpretation" difficulties involved in doing this, which explains why such tools do not really exist. Note that this tool does not work on HTML files with arbitrarily bad markup, as many HTML parsers do. It expects well-formed XHTML and interprets it into TLF. If Flash's XML parser chokes on the xhtml in the first place, then it's back to the drawing board.
TLF expects a flatter and more minimal document organization than XHTML supports. The translator must make hard decisions about what aspects of the format to respect, and which to discard. The Walflower XhtmlToTextFlow class handles this translation for us. It takes an XHTML document in XML format and returns a TLF TextFlow object. It manages to flatten the document into a valid TextFlow, while maintaining almost all of the DOM info that one would expect to see.
TLF expects a flatter and more minimal document organization than XHTML supports. The translator must make hard decisions about what aspects of the format to respect, and which to discard. The Walflower XhtmlToTextFlow class handles this translation for us. It takes an XHTML document in XML format and returns a TLF TextFlow object. It manages to flatten the document into a valid TextFlow, while maintaining almost all of the DOM info that one would expect to see.
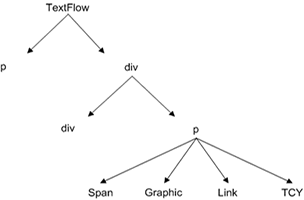
The translator accomplishes this by maintaining a stack of styles as the parser traverses the XHTML document. Some entities are translated directly into comparable TLF entities, such as "div", "p", and "span". Some entities are converted into functional equivalents, ie a "blockquote" becomes a kind of "div". And some entities will not contribute at all to the shape of the final TLF document, but serve only to style it. These tags are pushed onto a "style stack" that is then applied to a final TLF element. We assign styles to a TLF element through it's styleName property, separating multiple styles by commas. The styling logic further down the pipeline can then use this information however it sees fit.
Example
<html>
<body>
<div id="content">
<div id="section1">
<h1>Chapter 1</h1>
<p>The night was...</p>
<ul>
<li> Dark </li>
<li> Stormy </li>
</ul>
</div>
</div>
</body>
</html>
This should produce a TextFlow that looks like this:
<TextFlow xmlns="http://ns.adobe.com/textLayout/2008">
<div styleName="body">
<p styleName="div#content,div#section1,h1">
<span styleName="span">Chapter 1</span>
</p>
<p styleName="div#content,div#section1,p">
<span styleName="span">The night was...</span>
</p>
<div styleName="div#content,div#section1,ul">
<p styleName="li">
<span styleName="span">Dark</span>
</p>
<p styleName="li">
<span styleName="span">Stormy</span>
</p>
</div>
</div>
</TextFlow>
This addresses several major incompatibilities between these two formats. TextFlows are best thought of as a flat chunk of lines and inlines. There is no box/container model as in html, in which elements are often deeply nested and the visual arrangement between them highly specified in a stylesheet. But the stack of styles in each of our lines still enables us to maintain a lot of the original formatting, for example increasing the type size of the h1, changing the margin on the list lines, and adding numbers or bullets to each list item.
There are a few other TLF rules that we must respect. Paragraphs cannot be nested. Every paragraph requires a span. Divs cannot appear inside paragraphs. The translator accommodates all these rules and does the best it can to return a sensible flow.
There is one final trick this translator can accomplish. Many ePubs (such as those from Project Gutenberg) are far larger than is practical to cram into one TextFlow. Some of these documents are 100s of pages. So this library has a method to split XHTML documents into sensible smaller chunks. It does this by simply looking at header tags h1 through h6, and returning a new array of xml documents.
There are a few other TLF rules that we must respect. Paragraphs cannot be nested. Every paragraph requires a span. Divs cannot appear inside paragraphs. The translator accommodates all these rules and does the best it can to return a sensible flow.
There is one final trick this translator can accomplish. Many ePubs (such as those from Project Gutenberg) are far larger than is practical to cram into one TextFlow. Some of these documents are 100s of pages. So this library has a method to split XHTML documents into sensible smaller chunks. It does this by simply looking at header tags h1 through h6, and returning a new array of xml documents.
Source Code:
The XhtmlToTextFlow.as class.
An example flex project.
In subsequent posts, I'll look at the strategy I used to style flows of this shape, and how to parse the other parts of the ePub format.
Hi,
ReplyDeleteyours was a great help. But I have a query. What happens if our XHTML has a object tag (embedded swf for movie or audio). Can it pass it..if yes how can we render(dispaly) it.
Siddharth
ReplyDeleteI believe that object tags are discarded by the parser right now, but you could probably extend it to respect them. Your display code would have to call a Loader that pulled in the swf assets.
This comment has been removed by the author.
ReplyDeletehi I have got it.But I don't how can we display it.Is it possible to download it in epub format.
ReplyDeleteThis code just parses and translates the file. It does not add the textflow to the display list. Look for existing adobe documentation on working with text flows and TLF.
ReplyDelete