I was thrilled to discover the simple but effective static_model gem from the prolific Aaron Quint. It fills a much-needed hole in the Rails development process, and I'd like to advocate for its use as a standard workflow tool. I think my use of it is entirely counter to its original purpose, so it seems worth sharing.
Any web project even complex enough to require an interaction design prototype presents prototyping challenges. The usual deliverables like photoshop mockups, wireframes and static html mockups can all fail to illustrate important interaction concepts. Sometimes something needs to just get built to have a useful prototype.
Once you've decided to code something, a dizzying world of options opens up. These days, most mid-sized web apps are destined for Rails in their final form. But what is the best way to prototype a site in Rails? The Pragmatic crowd suggests that you don't prototype, and you just start building with scaffold and love your migrations, and go go go.
There are other approaches as well: many interaction designers will use Flash, JavaScript or even (shudder) PowerPoint to illustrate complex screen flows. But at this point you need to ask yourself how much you're ready to invest in throwaway code (or labor).
Look again at the archetypal e-commerce example from the Pragmatic books. If this were a real project -- I'm sorry about this dudes -- but you wouldn't start by building admin pages. You have a bunch of suits who need to buy into whatever this bookstore thing is we're building, and you need a finished looking storefront prototype for them to play with. It needs to have a couple books in it. It doesn't need a million pages for people to manage the store.
In the past, we built static html mockups of a limited number of pages and used this as a front end prototype. But now front-end requirements are much more complex, and the actual html prototypes are quite difficult to build without having the data they are presenting ... as data. In fact prototyping in Rails can be significantly faster than any alternative. Proper code abstraction makes iterating the design faster. Helper functions and simple loops can populate our interface with dummy data. Now we're getting somewhere.
So instead of building admin, we can slap some data behind all this using static_model. And that's the wonderful thing.
AQ's static model is a little gem that replaces ActiveRecord in your prototype. It reads data from YAML files into a model that masquerades as a normal ActiveRecord object. There are a few limitations, but they are easy to work around in a prototyping context.
To keep our bookstore example going, we'd simply make a YAML file with all our book info, read it in, and make a book model. We'd then spend all our prototyping time designing and building the appropriate front end features that need to be worked out (the reason you're making an interaction design prototype in the first place).
Once one has the green light to continue, then you can work up the schema for the real model and then build your Rails app normally. But the wonderful thing is that you can just continue to use all the views you created during the prototyping process while you build out the real model. And you'll have most of the data model worked out during this process to boot, unlike a more visually-oriented prototyping process.
Try it.
static_model is available at http://code.quirkey.com/static_model/
Monday, July 26, 2010
Wednesday, July 7, 2010
The Fastest Loop in Actionscript?
We learned a lot about Flash while optimizing the signal processing code in the StandingWave audio framework. Audio code consists almost entirely of endless tight loops, where each instruction could be executed hundreds of thousands of times per second. Native audio hackers traditionally optimize these types of loops in assembler, but in a sluggish VM like the Flash Player we don't have that option.
A lot of performance issues come from how the whole audio system interoperates...but at the lowest level, we're dead if we can't get all our simple low-level loops as fast as possible. Mixing is a core process, so let's look at the seemingly simple task of mixing two signals into a third, and see how we do.
A mixing loop would run many types in each sample event handler. Since we're measuring such small intervals, we'll have to mix *a lot* of stuff to get accurate time measurements. So our test condition works like this: 5 timer handlers trigger a function that each time, runs ten times, and mixes two 32k sample buffers. So in each test, we mix 5x 10x 32768 frames, or about 1.6 million sample frames.
What if these signals were represented as Arrays of Number in ActionScript? We might mix them like this:
In our test suite, this takes about 385ms. That is not fast.
StandingWave 2 modeled each signal as a Vector of Numbers. What if we mix two Vectors like this?
In our tests, this clocks in at about 68ms. It's possible to squeeze a little more by tweaking the loop, but this is pretty much the hard limit for a pure AS3-based approach. You could work with this, but we can do better.
Now, let's try working with the same loops in Adobe Alchemy. In StandingWave3 all the audio processing happens in C code that is compiled into a swc through the hopefully now-well-known Alchemy process.
In C, we have 3 arrays of floats. What happens if we write the same loop in C?
It comes in at about 41ms. We've already beat AS3 Vector performance, and we haven't broken a sweat yet. But now we're also in territory that is well mapped by the many explorers of C optimizations, so let's try some of those out.
You see a lot of audio code in C that looks like this, and it's usually pretty fast. But how does it do for us?
It's even faster, at about 32ms.
The pointer crawling is certainly nice and concise code, but there's still some inefficiencies hiding here. Doesn't it seem like there's some redundant incrementing going on? And do we really need to check to see if we're at the end of the buffer thirty-two thousand types? So, two things make this better. We only need 1 counter, and we're going to unroll the loop.
Joe laughed at me when I showed him this, but the old loop-unrolling trick works wonders here. In practical tests, 8x seems like the best compromise between speed-gain and code-bloat, so we'll go with that.
In this example, if "i" is the number of frames you need to process, we get the 8 factor and the remainder, and proceed like this:
It's hard to even measure this, since Flash's getTimer() function has millisecond-level accuracy, but this is on the order of 10ms. Wow!
And that's about the best I can do so far. So the final results are:
AS3 Array for loop: 385ms
AS3 Vector for loop: 68ms
for C loop: 41ms
Pointer crawling for C loop: 32ms
Unrolled 8x C while loop: 10 ms
And its hard to believe but in the grand scheme of things, 10ms for mixing 1.6 million samples is still kind of slow, but it's enough for us to be able to build something interesting.
All tests done on a 2.4 GHz MacBook with Flash Player 10.1 release version.
A lot of performance issues come from how the whole audio system interoperates...but at the lowest level, we're dead if we can't get all our simple low-level loops as fast as possible. Mixing is a core process, so let's look at the seemingly simple task of mixing two signals into a third, and see how we do.
A mixing loop would run many types in each sample event handler. Since we're measuring such small intervals, we'll have to mix *a lot* of stuff to get accurate time measurements. So our test condition works like this: 5 timer handlers trigger a function that each time, runs ten times, and mixes two 32k sample buffers. So in each test, we mix 5x 10x 32768 frames, or about 1.6 million sample frames.
What if these signals were represented as Arrays of Number in ActionScript? We might mix them like this:
for (var i:int=0; i<32768; i++) {
testArray3[i] = testArray1[i] + testArray2[i];
}
In our test suite, this takes about 385ms. That is not fast.
StandingWave 2 modeled each signal as a Vector of Numbers. What if we mix two Vectors like this?
for (var i:int=0; i<32768; i++) {
testVector3[i] = testVector1[i] + testVector2[i];
}
In our tests, this clocks in at about 68ms. It's possible to squeeze a little more by tweaking the loop, but this is pretty much the hard limit for a pure AS3-based approach. You could work with this, but we can do better.
Now, let's try working with the same loops in Adobe Alchemy. In StandingWave3 all the audio processing happens in C code that is compiled into a swc through the hopefully now-well-known Alchemy process.
In C, we have 3 arrays of floats. What happens if we write the same loop in C?
for (i=0; i<32768; i++) {
scratch3[i] = scratch2[i] + scratch1[i];
}
It comes in at about 41ms. We've already beat AS3 Vector performance, and we haven't broken a sweat yet. But now we're also in territory that is well mapped by the many explorers of C optimizations, so let's try some of those out.
You see a lot of audio code in C that looks like this, and it's usually pretty fast. But how does it do for us?
int i=32768
while(i--) {
*buffer3++ = *buffer2++ + *buffer1++;
}It's even faster, at about 32ms.
The pointer crawling is certainly nice and concise code, but there's still some inefficiencies hiding here. Doesn't it seem like there's some redundant incrementing going on? And do we really need to check to see if we're at the end of the buffer thirty-two thousand types? So, two things make this better. We only need 1 counter, and we're going to unroll the loop.
Joe laughed at me when I showed him this, but the old loop-unrolling trick works wonders here. In practical tests, 8x seems like the best compromise between speed-gain and code-bloat, so we'll go with that.
In this example, if "i" is the number of frames you need to process, we get the 8 factor and the remainder, and proceed like this:
int i=32768;
int count8 = i / 8;
int count1 = i % 8;
while(count8) {
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
count8--;
scratch3[count8] = scratch2[count8] + scratch1[count8];
}
while (count1--) {
scratch3[count1] = scratch2[count1] + scratch1[count1];
}
It's hard to even measure this, since Flash's getTimer() function has millisecond-level accuracy, but this is on the order of 10ms. Wow!
And that's about the best I can do so far. So the final results are:
AS3 Array for loop: 385ms
AS3 Vector for loop: 68ms
for C loop: 41ms
Pointer crawling for C loop: 32ms
Unrolled 8x C while loop: 10 ms
And its hard to believe but in the grand scheme of things, 10ms for mixing 1.6 million samples is still kind of slow, but it's enough for us to be able to build something interesting.
All tests done on a 2.4 GHz MacBook with Flash Player 10.1 release version.
Thursday, July 1, 2010
Working with ePub files in Flash and the Text Layout Framework
Walflower is an ActionScript framework for working with ePub files in Flash. You can download the code from github at http://www.github.com/maxl0rd/walflower.
EPub is an open-source format that has become one of the most popular ways of distributing non-DRM-protected eBooks. It is essentially a zip file containing a directory of XHTML documents, supporting files like images, and a variety of manifests and metadata that describe the shape of the document, the order it should be read, etc.
Walflower integrates the nice zip library written by nochump, which is not the fastest unzip routine ever seen, but it works quite nicely. It then parses all the book meta-data into various data structures that describe the book. Finally, it works through all the XHTML pages and parses them into TextFlows that can be displayed with the Text Layout Framework, as described in a previous post.
There is a sample project up in the repo that shows this in action here: http://github.com/maxl0rd/walflower/tree/master/examples/EPubExample/
It does not generate any output yet, but it would be a good starting point for a project based on this lib. The process of making sense of this file format was rather horrible, and I hope this code is useful to anyone on the same path.
You can see an example eBook reader that was made with this library over here:
walflower halloween book teaser.
EPub is an open-source format that has become one of the most popular ways of distributing non-DRM-protected eBooks. It is essentially a zip file containing a directory of XHTML documents, supporting files like images, and a variety of manifests and metadata that describe the shape of the document, the order it should be read, etc.
Walflower integrates the nice zip library written by nochump, which is not the fastest unzip routine ever seen, but it works quite nicely. It then parses all the book meta-data into various data structures that describe the book. Finally, it works through all the XHTML pages and parses them into TextFlows that can be displayed with the Text Layout Framework, as described in a previous post.
There is a sample project up in the repo that shows this in action here: http://github.com/maxl0rd/walflower/tree/master/examples/EPubExample/
It does not generate any output yet, but it would be a good starting point for a project based on this lib. The process of making sense of this file format was rather horrible, and I hope this code is useful to anyone on the same path.
You can see an example eBook reader that was made with this library over here:
walflower halloween book teaser.
Translating XHTML for the Text Layout Framework
Walflower is a set of ActionScript libraries to facilitate working with ePub documents in the Text Layout Framework. It can be found at http://www.github.com/maxl0rd/walflower. This is the first post in a series introducing some of its capabilities.
Source Code:
The XhtmlToTextFlow.as class.
An example flex project.
In subsequent posts, I'll look at the strategy I used to style flows of this shape, and how to parse the other parts of the ePub format.
One major piece of functionality that is missing from the core Text Layout Framework libraries is a means of converting the many forms of XHTML-based content into usable TLF formats. There are significant "interpretation" difficulties involved in doing this, which explains why such tools do not really exist. Note that this tool does not work on HTML files with arbitrarily bad markup, as many HTML parsers do. It expects well-formed XHTML and interprets it into TLF. If Flash's XML parser chokes on the xhtml in the first place, then it's back to the drawing board.
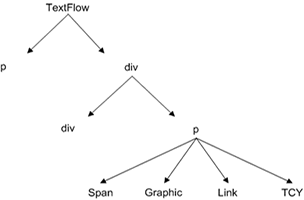
TLF expects a flatter and more minimal document organization than XHTML supports. The translator must make hard decisions about what aspects of the format to respect, and which to discard. The Walflower XhtmlToTextFlow class handles this translation for us. It takes an XHTML document in XML format and returns a TLF TextFlow object. It manages to flatten the document into a valid TextFlow, while maintaining almost all of the DOM info that one would expect to see.
TLF expects a flatter and more minimal document organization than XHTML supports. The translator must make hard decisions about what aspects of the format to respect, and which to discard. The Walflower XhtmlToTextFlow class handles this translation for us. It takes an XHTML document in XML format and returns a TLF TextFlow object. It manages to flatten the document into a valid TextFlow, while maintaining almost all of the DOM info that one would expect to see.
The translator accomplishes this by maintaining a stack of styles as the parser traverses the XHTML document. Some entities are translated directly into comparable TLF entities, such as "div", "p", and "span". Some entities are converted into functional equivalents, ie a "blockquote" becomes a kind of "div". And some entities will not contribute at all to the shape of the final TLF document, but serve only to style it. These tags are pushed onto a "style stack" that is then applied to a final TLF element. We assign styles to a TLF element through it's styleName property, separating multiple styles by commas. The styling logic further down the pipeline can then use this information however it sees fit.
Example
<html>
<body>
<div id="content">
<div id="section1">
<h1>Chapter 1</h1>
<p>The night was...</p>
<ul>
<li> Dark </li>
<li> Stormy </li>
</ul>
</div>
</div>
</body>
</html>
This should produce a TextFlow that looks like this:
<TextFlow xmlns="http://ns.adobe.com/textLayout/2008">
<div styleName="body">
<p styleName="div#content,div#section1,h1">
<span styleName="span">Chapter 1</span>
</p>
<p styleName="div#content,div#section1,p">
<span styleName="span">The night was...</span>
</p>
<div styleName="div#content,div#section1,ul">
<p styleName="li">
<span styleName="span">Dark</span>
</p>
<p styleName="li">
<span styleName="span">Stormy</span>
</p>
</div>
</div>
</TextFlow>
This addresses several major incompatibilities between these two formats. TextFlows are best thought of as a flat chunk of lines and inlines. There is no box/container model as in html, in which elements are often deeply nested and the visual arrangement between them highly specified in a stylesheet. But the stack of styles in each of our lines still enables us to maintain a lot of the original formatting, for example increasing the type size of the h1, changing the margin on the list lines, and adding numbers or bullets to each list item.
There are a few other TLF rules that we must respect. Paragraphs cannot be nested. Every paragraph requires a span. Divs cannot appear inside paragraphs. The translator accommodates all these rules and does the best it can to return a sensible flow.
There is one final trick this translator can accomplish. Many ePubs (such as those from Project Gutenberg) are far larger than is practical to cram into one TextFlow. Some of these documents are 100s of pages. So this library has a method to split XHTML documents into sensible smaller chunks. It does this by simply looking at header tags h1 through h6, and returning a new array of xml documents.
There are a few other TLF rules that we must respect. Paragraphs cannot be nested. Every paragraph requires a span. Divs cannot appear inside paragraphs. The translator accommodates all these rules and does the best it can to return a sensible flow.
There is one final trick this translator can accomplish. Many ePubs (such as those from Project Gutenberg) are far larger than is practical to cram into one TextFlow. Some of these documents are 100s of pages. So this library has a method to split XHTML documents into sensible smaller chunks. It does this by simply looking at header tags h1 through h6, and returning a new array of xml documents.
Source Code:
The XhtmlToTextFlow.as class.
An example flex project.
In subsequent posts, I'll look at the strategy I used to style flows of this shape, and how to parse the other parts of the ePub format.
Subscribe to:
Posts (Atom)